Probabilités et statistique
Les axes de recherche principaux de l'équipe "Probabilités et statistique" concernent essentiellement la modélisation stochastique et statistique, et le développement et l'optimisation de modèles de deep learning. Ses compétences méthodologiques, listées en anglais dans la première colonne du tableau ci-dessous, contribuent à des applications dans le domaine biomédical, en sciences environmentales, dans l'industrie, et plus généralement en lien avec l'utilisation croissante de l'intelligence artificielle pour résoudre des problèmes sociétaux :
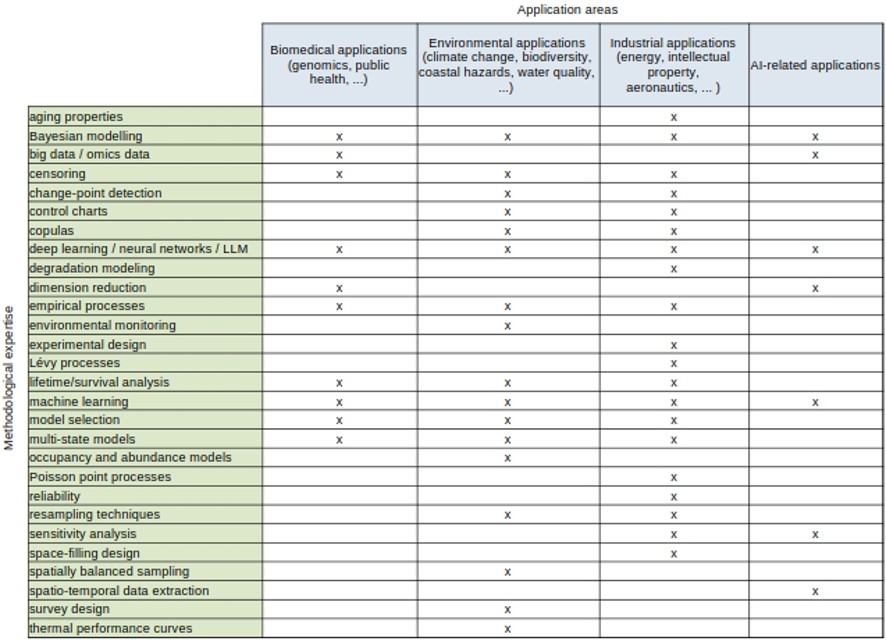
Dans le cadre d'applications biomédicales, l'équipe collabore étroitement avec des chercheurs en épidémiologie et en génétique. Elle développe des méthodes statistiques pour identifier des variants génétiques associés à différents cancers, via des études en génomique. Elle s'intéresse aux interactions gène-environnement et à l’exposome. Elle travaille aussi sur des modèles de survie appliqués à des données cliniques, notamment dans le cadre d’études sur le mélanome.
Dans le champ des applications environnementales, l'équipe développe des modèles d'occupation et d'abondance spatialement explicites de la biodiversité ainsi que la mise en œuvre de stratégies d’échantillonnage spatialement équilibrées pour la surveillance environnementale à long terme. Une des ses priorité est la prise en compte du changement climatique et de son impact sur les socio-écosystèmes et la biodiversité.
Dans le cadre de ses recherches en modélisation stochastique et statistique pour l'industrie, l'équipe s'intéresse à modèles de durées de vie et de dégradation et dispose de fortes compétences en fiabilité, maîtrise statistique des procédés et en plans d'expérience. Les recherches menées par l'équipe vont des développements théoriques aux applications, au travers notamment de collaborations avec des entreprises du secteur de l'énergie ou de l'aéronautique.
Enfin, l'équipe s'intéresse au développement et à l'optimisation de modèles de deep learning, avec un focus sur les applications de ces technologies à des problématiques sociétales ou des cas d'usage industriels. Ses travaux concernent notamment l'analyse de données textuelles à grande échelle ou le traitement des ambiguïtés de la langue naturelle dans des corpus spécifiques.